
How Do We Store Guides?
(October 2, 2017)
(Community guide by Jax)

When pac first approached me about developing VDU, I instantly had an idea of what technologies I wanted to use. Although I had never made a public website before, I have been learning and practicing the intricacies of web development for the past 3 years. Finally, I get to use those skills.
When we started planning, we had some pretty standard requirements for a site like ours—along with some requests from pac. The three main ones we focused on:
- Guides should be easy to publish and write
- We need to be able to build flexible queries for categorization
- It needs to be fast.
Enter MongoDB, Redis, and Node.
MongoDB
MongoDB is our main database for storing guides long-term. We use the mongoose module to interact with MongoDB from Node.
This is a cleaned up version of what our guide schema looks like:
{
tags: [String],
title: String,
summary: String,
content: String
}
Extremely simple, super effective, and because MongoDB is a NoSQL database, endlessly flexible for our needs.

Fun fact: Everything is a guide. This schema is so useful for serving editable text, why build a separate one just for storing static pages like /about, /contact, and /privacy? To prove it, here's a direct link to our about page viewed as a guide. Our static pages are equipped with a hidden tag. You can't browse those, but you can directly access them with the right link.
Combining Node, Redis, and MongoDB
Let's look at some API routes we built that take advantage of this feature-filled schema, and where they're used on the site.
GET /guide/<id>
Probably one of the most important routes on our site (you're using it right now), this one loads a guide by an ID. This is accessed through a HTTP GET request, and it returns a JSON of a single guide.
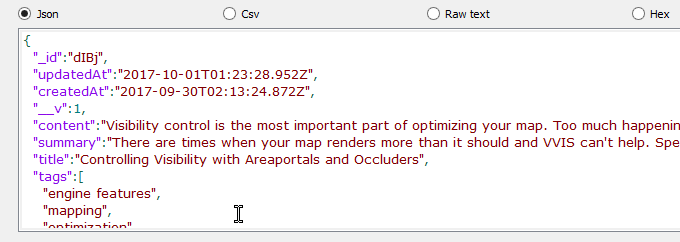
Here's an example response from our API. I chopped up some of the the lengthy fields so it doesn't flood your screen.
"guide": {
"_id": "gGOW",
"updatedAt": "2017-10-01T14:40:38.334Z",
"createdAt": "2017-09-22T00:51:35.086Z",
"content": "While the thought of optimizing...",
"title": "r_speeds and Optimizing Quake and GoldSrc Levels",
"tags": [
"goldsrc",
"mapping",
"optimization"
],
"views": "250"
}
I'll explain what each of these values are:
_id: This is the ID we use when loading a guide. This is randomly generated in our schema with a library called mongoose-shortid-nodeps.updatedAt&createdAt: These are managed by mongoose automatically via a{timestamps: true}option on our schema.content,title&tags: Same as in our schema. Contains the main content for the guide, with an array of tags for querying.views: Not always an accurate representation of actual views. This is how many times a guide has been requested with our API.
Woah, woah, woah, you track views in your database? That has to be slow!
Alas! We can discuss caching on VDU; a very intriguing topic, as it can improve performance of dynamic sites by almost 100%.
We use Redis as an in-memory key-value store for caching and storing data. What all that means (specifically the in-memory part) is Redis is blazing fast.
Back to the views performance concern, we use Redis to store a ZINCRBY command to increase the view count for that guide ID, and then return it in the response JSON.
Another huge use case of Redis for this route is caching the actual guide. We could be getting a lot of requests at once, and hitting our database for data that rarely changes is really pointless and slow. Whenever a guide is created, we put it in the cache as a stringified JSON under the key guide:<guide ID>. This changes the retrieval time from 300ms average on our database to just 100ms out of Redis. We keep guides in the cache until they're edited or deleted. The former leading to an overwrite in the cache.
POST /guides
Equally important, but more frequently used is our route for querying all our guides. This route is so flexible and useful that we use it almost everywhere. Our frontpage, browse, and guide pages all make use of this route to list guides. This route is handled with a POST request, and it takes a JSON query object.
This is a query taken from the frontpage where we browse for the top three newest GoldSrc tools:
query: {
tags: ["goldsrc"]
excludeTags: ["tools"]
excludeGuides: [],
search: "",
loose: false,
skip: 0,
limit: 3
}
Here's what each of these do:
tags: I love tags. They're the most useful feature of the entire site. This is an array of all the tags to include in the query.excludeTags: Similar totags, this excludes all tags you don't want to see in your query. This uses MongoDB's$ninoperator.excludeGuides:This is a feature I added for the "relevant guides" section at the bottom of guides. It excludes any guide IDs put into the array.
The above fields can be in array, or in the a string if you only need one. For example: ["goldsrc", "source"] compared to "source".
search:Surprise! We have searching functionality, but it's not built into the site yet. This uses MongoDB's$textoperator.loose:This changes the MongoDB operator on thetagsfield from$all(a strict query) to$in. Strict queries have to match all tags, while loose queries can match any of them.skip:This is how far to skip from the start of the query. We use this for the "load more" function on the browse pages.limit:Limits the amount of guides to return. This is capped at25by default.
This request responds with the query, and an array of the resulting guides.
Don't these queries also hit your database? Where's the caching!?
Once again, we use Redis caching to enhance speed. One problem, we can't easily identify the cache keys for queries. With single guides we have an ID, but for queries we need some way to flatten it. A quick thought came to mind—hashes.
After cleaning up the query, like sorting the tags in alphabetical order(that's why they're alphabetized on the site), we run it through the object-hash module. This converts the JSON query object into an SHA-1 hash. This is what we use as our key for identifying the query in Redis. It sounds really complex, but this is faster than going to our database.
As for handling cache invalidation, we clear the entire query cache upon a guide creation/update. All queries are stored for 24 hours except for search queries which are only held for 2 minutes. The reason for the lower limit on text search is, if someone is trying different strings, we don't want to store all 50 typos they totally made.
When an admin is logged in, the query has an admin: true property added to it which gives it a different cache. This allows us to view all guides, including hidden tags.
I look forward to documenting further development information, such as our CDN and frontend technology. If you have any questions, check out our contact page.